

Ijraset Journal For Research in Applied Science and Engineering Technology
Insight Cart- A Product Analysis Website Using Web Scraping and Machine Learning
Authors: Abhishek K S, Ravindra S, Archana B H, Abhishek H J, Abhishek S Palankar
DOI Link: https://doi.org/10.22214/ijraset.2024.65845
Certificate: View Certificate
Abstract
This paper presents an innovative approach to e-commerce data analysis using web scraping and machine learning techniques. By aggregating data from platforms like Amazon, eBay, Snapdeal, and Ajio, the system facilitates product comparison and price prediction. Leveraging state-of-the-art scraping tools such as Selenium and BeautifulSoup, and machine learning algorithms, including K-Means clustering and Linear Regression, the system ranks products and forecasts price trends. A detailed graph showcasing predicted price trends over time provides actionable insights for consumer decision-making. Results emphasize the integration of analytics and data visualization to enhance the e-commerce experience.
Introduction
I. INTRODUCTION
The e-commerce industry is experiencing exponential growth, presenting consumers with an overwhelming number of products and prices across multiple platforms. Identifying the best time to purchase or comparing similar products often requires considerable effort due to scattered and inconsistent data. This paper addresses these challenges by introducing a system that integrates web scraping and machine learning (ML). Using data from platforms such as Amazon , Ajio, Snapdeal and eBay, the system automates product ranking and predicts price trends, enhancing both consumer convenience and decision-making efficiency. Key outputs include interactive graphs illustrating predicted price trajectories for various products.
II. LITERATURE REVIEW
Research on web scraping and its applications has highlighted its role in collecting structured data from unstructured web content. Combining insights from various studies highlights the effectiveness of advanced web scraping methods [1], the role of scraping in structured data integration [2]
- Aswad et al. (2023): Demonstrated the use of web scraping for product comparison websites, integrating recommendation algorithms to enhance user experience [1].
- Srividhya et al. (2019): Emphasized data visualization post-web scraping to simplify consumer decision-making [2].
- Bo Zhao (2017): Discussed advanced web scraping techniques involving tools like BeautifulSoup and Selenium [3].
These studies underline the growing relevance of web scraping in extracting actionable insights from large datasets. Combining this with machine learning amplifies its potential for innovative solutions in e-commerce.
III. METHODOLOGY
A. Web Scraping
The platform uses Python libraries such as BeautifulSoup and Selenium to scrape data from Amazon, eBay, Snapdeal, and Ajio. These tools are consistent with strategies discussed in research for efficient data extraction [1, 2]. The scraped data includes product titles, prices, ratings, and URLs. To ensure ethical scraping, the system adheres to site policies outlined in robots.txt files, aligning with ethical guidelines mentioned in recent studies [3].
B. Data Preprocessing
Scraped data is cleaned to handle inconsistencies:
- Prices are normalized by removing currency symbols and commas.
- Missing ratings are replaced with default values.
C. Clustering and Ranking
Clustering is performed using the K-Means algorithm to group products based on normalized price and rating. This approach is consistent with studies emphasizing machine learning's role in effective product sorting and ranking [1, 4]. Each product is assigned a predicted score based on its proximity to the centroid and user rating, ensuring relevance and accuracy in recommendations [3].
D. Price Prediction
Linear regression models are employed to predict future price trends, a method validated by prior studies emphasizing the utility of predictive analytics for consumer insights [4]. This approach provides users with actionable predictions on cost changes over time, enhancing decision-making efficiency.
E. Flowchart of System Workflow
The following Figure 1 flowchart illustrates the system workflow for product analysis. It depicts the stages from user input to detecting future price trends using linear regression.
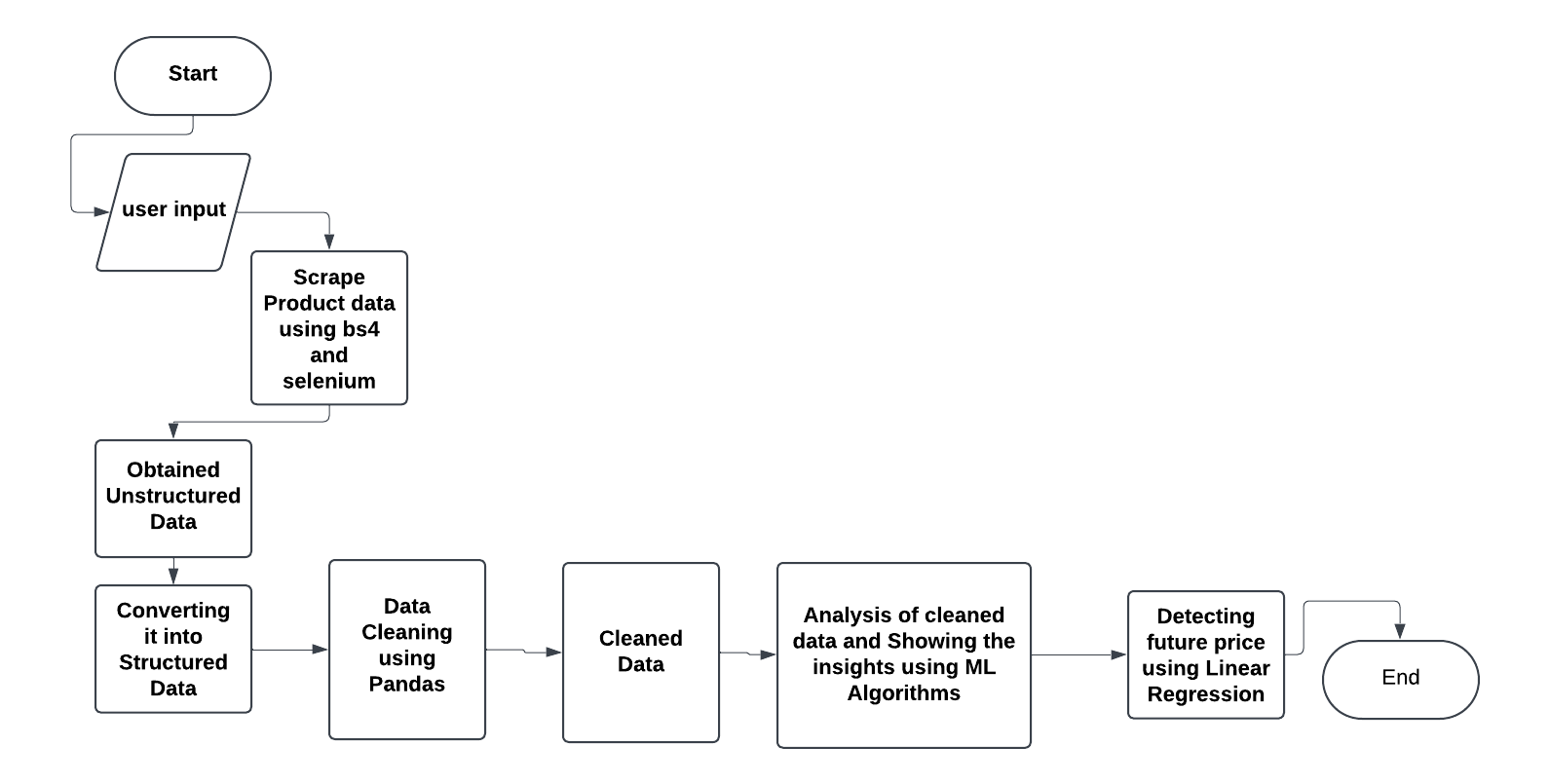
Fig. 1 Workflow of the Product Analysis System
IV. RESULTS AND DISCUSSION
A. Data Extraction Performance
The system successfully scraped entries across four platforms. Challenges included handling CAPTCHAs and dynamic JavaScript content.
B. Product Ranking
Figure 2 shows K-Means clustering effectively segmented products into three clusters, highlighting affordability and quality differences. Consumers can easily identify products tailored to their preferences.
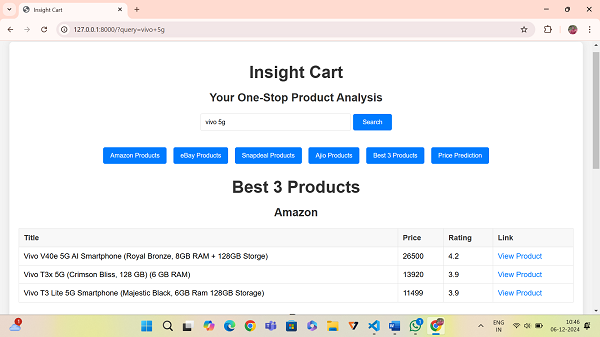
Fig. 2 Best three Products using K Means Clustering
C. Price Prediction Graph
Figure 3 showcases the price prediction graph for Amazon products. The graph highlights:
- Current price trends.
- Predicted prices for the next 10 time steps.
- Insights into seasonal price fluctuations or market trends.
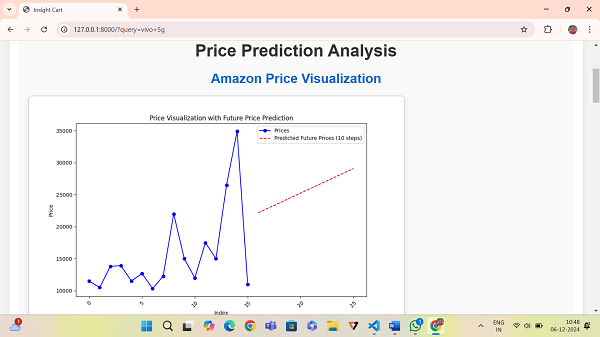
Fig. 3 The Price Predicted for the next 10 steps
D. Scraped Data Snapshot
Figure 4 displays an example of scraped data from the system interface, showcasing extracted product details such as title, price, and ratings.
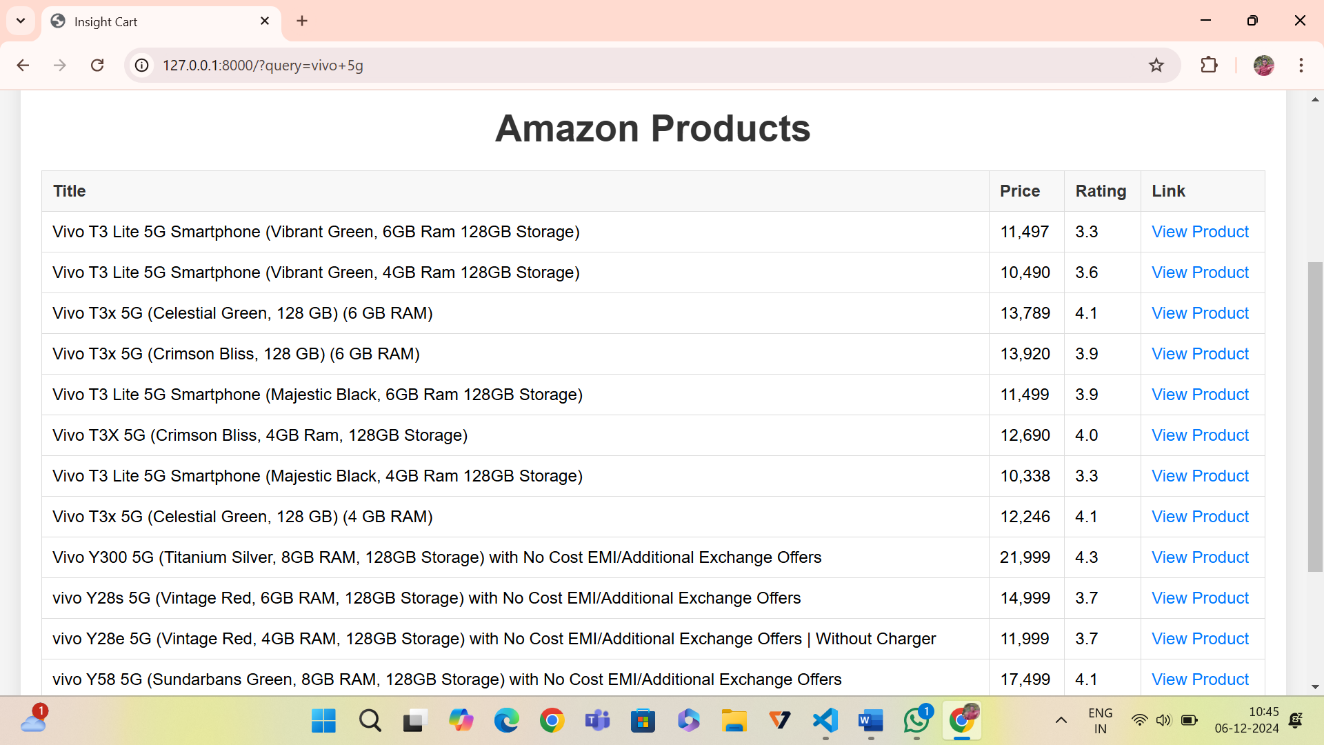
Fig. 4 The scraped data
E. Discussion
While the system offers robust analytics, limitations include:
- Data Completeness: Missing data from platforms due to restricted APIs.
- Scalability: Scraping large datasets in real-time requires additional resources.
Conclusion
This study demonstrates the efficacy of combining web scraping and machine learning to create an intelligent product comparison tool. The integration of clustering and price prediction provides users with a dynamic, data-driven shopping experience. Future enhancements could include: 1) Incorporating deep learning for more nuanced recommendations [4]. 2) Expanding data sources to include user reviews and social media trends. 3) Developing mobile applications for broader accessibility.
References
[1] Aswad Shaikh, Aniket Sonmali, and Soham Wakade, \"Product Comparison Website using Web Scraping and Machine Learning,\" Student at Department of Information Technology, Atharva College of Engineering, Mumbai, Maharashtra, India. [2] V. Srividhya and P. Megala, \"Scraping and Visualization of Product Data from E-commerce Websites,\" Dept of Computer Science, Avinashilingam Institute for Home Science and Higher Education for Women, Coimbatore, Tamilnadu, India. [3] B. Zhao, \"Web Scraping,\" College of Earth, Ocean, and Atmospheric Sciences, Oregon State University, Corvallis, OR, USA. [4] C. Lotfi, S. Srinivasan, M. Ertz, and I. Latrous, \"Web Scraping Techniques and Applications: A Literature Review,\" Labo NFC, University of Quebec at Chicoutimi, 555 Boulevard de l’Université, Saguenay (QC), Canada. [5] M. Fra?o, \"Web Scraping as a Data Source for Machine Learning Models and the Importance of Preprocessing Web Scraped Data,\" University of Twente, The Netherlands. [6] S. C. M. de S. Sirisuriya, \"Importance of Web Scraping as a Data Source for Machine Learning Algorithms - Review,\" Department of Computer Science, Faculty of Computing, General Sir John Kotelawala Defence University, Sri Lanka. [7] R. Praba, G. Darshan, K. T. Roshanraj, and B. Surya Prakash, \"Study On Machine Learning Algorithms,\" Department of Information Technology, Dr. N.G.P. Arts and Science College, Coimbatore, Tamil Nadu, India. [8] T. S. Singh and H. Kaur, \"Review Paper on Django Web Development,\" Department of Computer Application, Rayat Bahra University. [9] Data Visualization workshop, Tim Grobmann and Mario Dobler, Packt Publishing, ISBN 9781800568112 [10] https://docs.python.org/3/ [11] https://pypi.org/project/beautifulsoup4/ [12] https://pypi.org/project/requests/ [13] https://www.djangoproject.com/ [14] https://www.selenium.dev/documentation/ [15] https://docs.djangoproject.com/en/stable/ [16] Adrian Holovaty, Jacob Kaplan Moss, The Definitive Guide to Django: Web Development Done Right, Second Edition, Springer-Verlag Berlin and Heidelberg GmbH & Co. KG Publishers, 2009 [17] S. Sridhar, M Vijayalakshmi “Machine Learning”,Oxford,2021. [18] https://scikit-learn.org/stable/documentation.html
Copyright
Copyright © 2024 Abhishek K S, Ravindra S, Archana B H, Abhishek H J, Abhishek S Palankar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65845
Publish Date : 2024-12-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online